一、如何做T检验 并对其进行显著性差异的评价?
你在回答怎么做T检验中提到的成对,单尾,等方差,等方差有点不明白 我用的是2003的EXECL 可以帮帮我不。
在忙着做论文啊!!而且我能找到的没有统计分析 只能是从插入函数里面找到公式。
我照你的说法做了一次同样也出了数据但是又要怎样才能评价它的显著性呢?因为P<;
0.05和P<;
0.01 这两个又怎么来评价 我是学体育的现在做毕业论文用到了,头都要大了!!补充: 我的问题现在是出现在怎么才能算出是不是真的小于0.05或者0.01了 而且我发的图你也看到了 我的那个选择就没有什么等方差,然后就是我的论文是写训练后的有明显性差异的,我对数学有点敏感,请多多见谅。
补充: 出来的结果大于1以上啊! 补充: 不是吧,我看了一些关于这种研究的论文 我看见他们列出来的T值 也有好多都是大于0.05的 而且达到了2以上 所以就有点不明白了。
补充: 不是上面这些数据的 还有其他的数据上面的我只是举的列子,我按照你的方法试试看 主要是有些我测出来了 就在2左右或者是0.几的 不是0.0几的问题。

二、怎样用 Python 写一个股票自动交易的程序
你就是想找个软件或者券商的接口去上传交易指令,你前期的数据抓取和分析可能python都写好了,所以差这交易指令接口最后一步。
对于股票的散户,正规的法子是华宝,国信,兴业这样愿意给接口的券商,但貌似开户费很高才给这权利,而且只有lts,ctp这样的c++接口,没python版就需要你自己封装。
还有的办法是wind这样的软件也有直接的接口,支持部分券商,但也贵,几万一年是要的,第三种就是走野路子,鼠标键盘模拟法,很复杂的,就是模拟键盘鼠标去操作一些软件,比如券商版交易软件和大智慧之类的。
还有一种更野的方法,就是找到这些软件的关于交易指令的底层代码并更改,我百度看到的,不知道是不是真的可行。
。
散户就这样,没资金就得靠技术,不过我觉得T+1的规则下,预测准确率的重要性高于交易的及时性,花功夫做数据分析就好,交易就人工完成吧

三、如何使用python对基金投资收益进行回测
详细建议您可以去看看掘金量化的Python接口文档,我们team有位大神挺懒的就是用掘金来做回测,免费的~回测是否具有统计意义看你的策略逻辑和交易样本的数量。
个人认为可以直观地观测策略的盈亏特性,如适合什么属性的标的,在怎样的市场环境下能盈利(或亏损)。
因此对未来行情的表现具有一定指导意义。
要注意的是,参数拟合好后把策略扔到样本外的历史行情观察表现,评估策略的适应性和泛化能力。
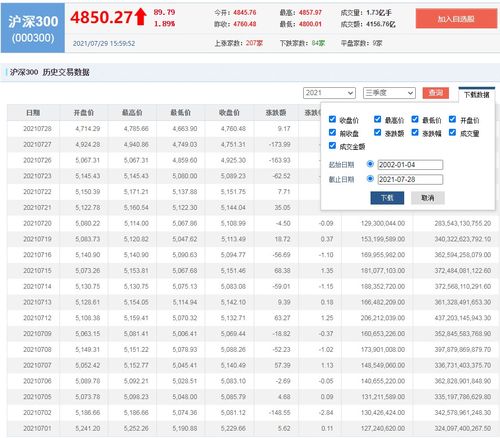
四、股票收益的期望和标准差计算。
听了我这段做股票的心得,你一定有很大的收获。
我觉得做股票吧,首先,心态要好,创造财富也得有好心情。
中国的股市,波段操作的赢利范围和可行性最大,另外,选取的个股,也必须跟随主力的动向,这样就不会让自己的资金冒险。
为了把握最理想的买卖点,必须有主力的带动和证券技术部门的老师指引去操作,这样才能达到在股市中长期的稳定赢利。
下面我给大家推荐一位在股市中比较资深的操盘老师,主要的实战操作,才能让我们信服,这位老师的操作平台资料就在我的空间里,相信自己的眼光,关注一段时间后,你会发现,做股票,这才叫实力!

五、如何用origin进行t检验
上图为SPSS做的配对样本T检验,得出的结果为P值为0.072,在显著性水平为0.05的情况下,是接收原假设,即该减肥药无效

六、用GARCH(1,1)模型对股票收盘价收益率序列建模,如何在eviews软件中得出收益率序列的波动性方差?
接分啦。
。
。
找到一篇不错的文章楼主看下,参考资料:2.关联规则挖掘过程、分类及其相关算法2.1关联规则挖掘的过程关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Frequent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules)。
关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(Large Itemsets)。
高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。
一项目组出现的频率称为支持度(Support),以一个包含A与B两个项目的2-itemset为例,我们可以经由公式(1)求得包含项目组的支持度,若支持度大于等于所设定的最小支持度(Minimum Support)门槛值时,则称为高频项目组。
一个满足最小支持度的k-itemset,则称为高频k-项目组(Frequent k-itemset),一般表示为Large k或Frequent k。
算法并从Large k的项目组中再产生Large k+1,直到无法再找到更长的高频项目组为止。
关联规则挖掘的第二阶段是要产生关联规则(Association Rules)。
从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(Minimum Confidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。
例如:经由高频k-项目组所产生的规则AB,其信赖度可经由公式(2)求得,若信赖度大于等于最小信赖度,则称AB为关联规则。
就沃尔马案例而言,使用关联规则挖掘技术,对交易资料库中的纪录进行资料挖掘,首先必须要设定最小支持度与最小信赖度两个门槛值,在此假设最小支持度min_support=5% 且最小信赖度min_confidence=70%。
因此符合此该超市需求的关联规则将必须同时满足以上两个条件。
若经过挖掘过程所找到的关联规则「尿布,啤酒」,满足下列条件,将可接受「尿布,啤酒」的关联规则。
用公式可以描述Support(尿布,啤酒)>;
=5%且Confidence(尿布,啤酒)>;
=70%。
其中,Support(尿布,啤酒)>;
=5%于此应用范例中的意义为:在所有的交易纪录资料中,至少有5%的交易呈现尿布与啤酒这两项商品被同时购买的交易行为。
Confidence(尿布,啤酒)>;
=70%于此应用范例中的意义为:在所有包含尿布的交易纪录资料中,至少有70%的交易会同时购买啤酒。
因此,今后若有某消费者出现购买尿布的行为,超市将可推荐该消费者同时购买啤酒。
这个商品推荐的行为则是根据「尿布,啤酒」关联规则,因为就该超市过去的交易纪录而言,支持了“大部份购买尿布的交易,会同时购买啤酒”的消费行为。
从上面的介绍还可以看出,关联规则挖掘通常比较适用与记录中的指标取离散值的情况。
如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
2.2关联规则的分类按照不同情况,关联规则可以进行分类如下:1.基于规则中处理的变量的类别,关联规则可以分为布尔型和数值型。
布尔型关联规则处理的值都是离散的、种类化的,它显示了这些变量之间的关系;
而数值型关联规则可以和多维关联或多层关联规则结合起来,对数值型字段进行处理,将其进行动态的分割,或者直接对原始的数据进行处理,当然

七、如何用origin进行t检验
1、打开图示的主界面,直接按照Analysis→Fitting→Linear Fit的顺序进行点击。
2、下一步弹出新的窗口,需要根据实际情况来设置对应的参数。
3、这个时候如果没问题,就选择Yes并确定OK。
4、这样一来会得到相关的结果,即可用origin对回归方程进行t检验与F检验了。
注意事项:T检验对数据的正态性有一定的耐受能力。
如果数据只是稍微偏离正态,结果仍然是稳定的。
如果数据偏离正态很远,则需要考虑数据转换或采用非参数方法分析。
两个独立样本T检验的原假设为两个总体均值之间不存在显著性差异,需分两步完成:①利用F检验进行两总体方差的同质性判断;
②根据方差同质性的判断,决定T统计量和自由度计算公式,进而对T检验的结果给予恰当的判定。

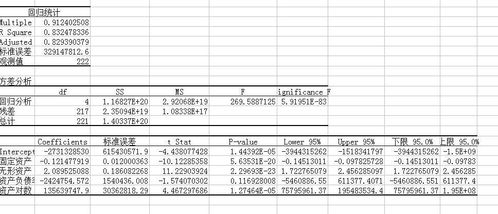
八、如何用回归直线法求资产的系统风险系数β
从本世纪七十年代以来,西方学者对CAPM进行了大量的实证检验。
这些检验大体可以分为三类: 1.风险与收益的关系的检验 由美国学者夏普(Sharpe)的研究是此类检验的第一例。
他选择了美国34个共同基金作为样本,计算了各基金在1954年到1963年之间的年平均收益率与收益率的标准差,并对基金的年收益率与收益率的标准差进行了回归,他的主要结论是: a、在1954—1963年间,美国股票市场的收益率超过了无风险的收益率。
b、 基金的平均收益与其收益的标准差之间的相关系数大于0.8。
c、风险与收益的关系是近似线形的。
2.时间序列的CAPM的检验 时间序列的CAPM检验最著名的研究是Black,Jensen与Scholes在1972年做的,他们的研究简称为BJS方法。
BJS为了防止β的估计偏差,采用了指示变量的方法,成为时间序列CAPM检验的标准模式,具体如下: a、利用第一期的数据计算出股票的β系数。
b、 根据计算出的第一期的个股β系数划分股票组合,划分的标准是β系数的大小。
这样从高到低系数划分为10个组合。
c、采用第二期的数据,对组合的收益与市场收益进行回归,估计组合的β系数。
d、 将第二期估计出的组合β值,作为第三期数据的输入变量,利用下式进行时间序列回归。
并对组合的αp进行t检验。
其中:Rft为第t期的无风险收益率 Rmt为市场指数组合第t期的收益率 βp指估计的组合β系数 ept为回归的残差 BJS对1931—1965年间美国纽约证券交易所所有上市公司的股票进行了研究,发现实际的回归结果与理论并不完全相同。
BJS得出的实际的风险与收益关系比CAPM 模型预测的斜率要小,同时表明实际的αp在β值大时小于零,而在β值小时大于零。
这意味着低风险的股票获得了理论预期的收益,而高风险股票获得低于理论预测的收益。
3.横截面的CAPM的检验 横截面的CAPM检验区别于时间序列检验的特点在于它采用了横截面的数据进行分析,最著名的研究是Fama和Macbeth(FM)在1973年做的,他们所采用的基本方法如下: a、根据前五年的数据估计股票的β值。
b、 按估计的β值大小构造20个组合。
c、计算股票组合在1935年—1968年间402个月的收益率。
d、 按下面的模型进行回归分析,每月进行一次,共402个方程。
Rp=g0+g1bp+g2bp2+g3sep+ep 这里:Rp为组合的月收益率、 βp为估计的组合β值 bp2为估计的组合β值的平方 sep为估计βp值的一次回归方程的残差的标准差 g0、g1、g2、g3为估计的系数,每个系数共402个估计值 e、对四个系数g0、g1、g2、g3进行t检验 FM结果表明: ①g1的均值为正值,在95%的置信度下可以认为不为零,表明收益与β值成正向关系 ②g2、g3在95%的置信度下值为零,表明其他非系统性风险在股票收益的定价中不起主要作用。
1976年Richard·Roll对当时的实证检验提出了质疑,他认为:由于无法证明市场指数组合是有效市场组合,因而无法对CAPM模型进行检验。
正是由于罗尔的批评才使CAPM的检验由单纯的收益与系统性风险的关系的检验转向多变量的检验,并成为近期CAPM检验的主流。
最近20年对CAPM的检验的焦点不是 ,而是用来解释收益的其它非系统性风险变量,这些变量往往与公司的会计数据相关,如公司的股本大小,公司的收益等等。
这些检验结果大都表明:CAPM模型与实际并不完全相符,存在着其他的因素在股票的定价中起作用。

九、对 “T检验”表中的数据进行T检验操作,并判断结果
上图为SPSS做的配对样本T检验,得出的结果为P值为0.072,在显著性水平为0.05的情况下,是接收原假设,即该减肥药无效
参考文档
下载:python怎么对股票收益率进行t检验.pdf《股票页面金额是什么意思》《信义电源股票代码是什么》《股票市场多方和空方都是什么意思》《股票为什么跌到底点位》《炒股软件天狼好用吗》下载:python怎么对股票收益率进行t检验.doc更多关于《python怎么对股票收益率进行t检验》的文档...声明:本文来自网络,不代表【股识吧】立场,转载请注明出处:https://www.gupiaozhishiba.com/store/34753000.html



