一、如何利用Python爬虫从网页上批量获取想要的信息
python是一款应用非常广泛的脚本程序语言,谷歌公司的网页就是用python编写。
python在生物信息、统计、网页制作、计算等多个领域都体现出了强大的功能。
python和其他脚本语言如java、R、Perl 一样,都可以直接在命令行里运行脚本程序。
工具/原料python;
CMD命令行;
windows操作系统方法/步骤1、首先下载安装python,建议安装2.7版本以上,3.0版本以下,由于3.0版本以上不向下兼容,体验较差。
2、打开文本编辑器,推荐editplus,notepad等,将文件保存成 .py格式,editplus和notepad支持识别python语法。
脚本第一行一定要写上 #!usr/bin/python表示该脚本文件是可执行python脚本如果python目录不在usr/bin目录下,则替换成当前python执行程序的目录。
3、编写完脚本之后注意调试、可以直接用editplus调试。
调试方法可自行百度。
脚本写完之后,打开CMD命令行,前提是python 已经被加入到环境变量中,如果没有加入到环境变量,请百度4、在CMD命令行中,输入 “python” + “空格”,即 ”python “;
将已经写好的脚本文件拖拽到当前光标位置,然后敲回车运行即可。

二、如何通过Python获取外汇数据
这个和用不用python没啥关系,是数据来源的问题。
调用淘宝API,使用 api相关接口获得你想要的内容,我 记得api中有相关的接口,你可以看一下接口的说明。
用python做爬虫来进行页面数据的获龋 希望能帮到你。
三、有木有做数据分析师的女生?
数据分析师已经是目前只具有前景的职业之一,作为一名女生数据分析师成员,分享下到底女生适合做数据分析师吗?而数据分析师适合女生嘛,下面看下数据分析师是干嘛的。
数据分析这个行业也有很多细分领域的,比如做业务支持,你可以朝技术方面深入,做商业智能方面的专家。
你也可以朝管理和战略决策方面发展,做职业经理人。
我觉得无论什么工作兴趣最重要,要做数据分析师最基本的就是不讨厌数字,如果你跟他讲那个指标是通过怎么样的乘除加减得到的,他会觉得不耐烦,那么显然他不适合做数据分析;
如果对数据较敏感,能够一眼发现异常值,数据分布情况,当然是最好的。
再则就是逻辑性,可以让他试试爱因斯坦的那道经典的逻辑题,看看能否解出来,需要多久;
逻辑思维对数据分析尤其重要,不然会被各种指标的定义规则、与业务的联系纠结死,逻辑思维好的人写SQL等数据处理脚本也会更加高效。
接着是业务理解能力,最简单的就是让他定义下网站的目标是什么,哪些指标可以作为KPI,用户从进入网站到达成网站目标的整个过程是怎么实现转化的,能否画出业务流程图。
如果偏技术则需要懂一些数据库结构和SQL,如果偏展现需要考验下对图表的掌控能力,什么时候用什么图表合适,甚至如何配色。
最后就是细心、耐心和交流能力,做数据分析有时会很纠结,细心和耐心是必需的,好的交流能力可以让数据分析师更好地阐述清楚各类问题。
这些都是比较基础的东西,也是短期难以培养起来的技能。
至于另外业务相关的一些知识,可以通过培训获取,问一个未接触过你的网站业务的人一些业务知识其实有些不公平,其实如果具备上面几点,一旦熟悉网站和业务之后,一定会成为优秀的数据分析师。
1、问问他喜欢什么,平时对什么事情有兴趣,然后挖掘这些事情中他关注什么数据,比如买彩票?炒股?看nba?其实里面都有很多数据,他在他喜欢的领域,如果能对数据如数家珍,对数据的解读能到位,(比如对某个nba 球星的数据和所对应的表现状态做评论)至少说明他有很强的数据感。
数据感是做数据分析的第一要务。
2、问问他对数据分析的理解和目标,看看他是怎么认识这份工作的。
3、常见数据分析误区有非常多经典范例,给出几个测试题(容易产生误判的数据案例)让他分析解读一下。
4、典型场景分析,在某些业务场合中,最需要关注什么数据,如何解读其中的一些数据特征。

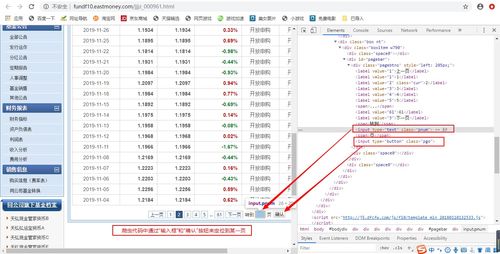
四、如何用爬虫获取基金数据
用前嗅的ForeSpider数据采集软件,可以采集基金数据、股票数据等。
同时ForeSpider内部集成了数据挖掘的功能,可以快速进行聚类分类、统计分析等,采集结果入库后就可以形成分析报表。
ForeSpider是可视化的通用性爬虫软件。
简单配置几步就可以采集。
如果网站比较复杂,软件自带爬虫脚本语言,通过写几行脚本,就可以采集所有的公开数据。
软件还自带免费的数据库,数据采集直接存入数据库,也可以导出成excel文件。
如果自己不想配置,前嗅可以配置采集模板。
可以下载一个免费版试一试,免费版不限制功能,没有到期时间。
五、Python中怎么用爬虫爬
Python爬虫可以爬取的东西有很多,Python爬虫怎么学?简单的分析下:如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
安居客、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
拉勾网、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。
爬虫是入门Python最好的方式,没有之一。
Python有很多应用的方向,比如后台开发、web开发、科学计算等等,但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习Python数据分析、web开发甚至机器学习,都会更得心应手。
因为这个过程中,Python基本语法、库的使用,以及如何查找文档你都非常熟悉了。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。
比如有人认为学爬虫必须精通 Python,然后哼哧哼哧系统学习 Python 的每个知识点,很久之后发现仍然爬不了数据;
有的人则认为先要掌握网页的知识,遂开始 HTMLCSS,结果入了前端的坑,瘁……但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现,但建议你从一开始就要有一个具体的目标。
在目标的驱动下,你的学习才会更加精准和高效。
那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。
这里给你一条平滑的、零基础快速入门的学习路径。
1.学习 Python 包并实现基本的爬虫过程2.了解非结构化数据的存储3.学习scrapy,搭建工程化爬虫4.学习数据库知识,应对大规模数据存储与提取5.掌握各种技巧,应对特殊网站的反爬措施6.分布式爬虫,实现大规模并发采集,提升效率
六、如何用python 取所有股票一段时间历史数据
各种股票软件,例如通达信、同花顺、大智慧,都可以实时查看股票价格和走势,做一些简单的选股和定量分析,但是如果你想做更复杂的分析,例如回归分析、关联分析等就有点捉襟见肘,所以最好能够获取股票历史及实时数据并存储到数据库,然后再通过其他工具,例如SPSS、SAS、EXCEL或者其他高级编程语言连接数据库获取股票数据进行定量分析,这样就能实现更多目的了。

七、如何用python获取股票数据
在Python的QSTK中,是通过s_datapath变量,定义相应股票数据所在的文件夹。
一般可以通过QSDATA这个环境变量来设置对应的数据文件夹。
具体的股票数据来源,例如沪深、港股等市场,你可以使用免费的WDZ程序输出相应日线、5分钟数据到s_datapath变量所指定的文件夹中。
然后可使用Python的QSTK中,qstkutil.DataAccess进行数据访问。

参考文档
声明:本文来自网络,不代表【股识吧】立场,转载请注明出处:https://www.gupiaozhishiba.com/read/33081740.html



