一、聚类分析的主要步骤
聚类分析的主要步骤聚类分析的主要步骤1.数据预处理,2.为衡量数据点间的相似度定义一个距离函数,3.聚类或分组,4.评估输出。
数据预处理包括选择数量,类型和特征的标度,它依靠特征选择和特征抽取,特征选择选择重要的特征,特征抽取把输入的特征转化为一个新的显著特征,它们经常被用来获取一个合适的特征集来为避免“维数灾”进行聚类,数据预处理还包括将孤立点移出数据,孤立点是不依附于一般数据行为或模型的数据,因此孤立点经常会导致有偏差的聚类结果,因此为了得到正确的聚类,我们必须将它们剔除。
既然相类似性是定义一个类的基础,那么不同数据之间在同一个特征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特征标度的多样性,距离度量必须谨慎,它经常依赖于应用,例如,通常通过定义在特征空间的距离度量来评估不同对象的相异性,很多距离度都应用在一些不同的领域,一个简单的距离度量,如Euclidean距离,经常被用作反映不同数据间的相异性,一些有关相似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概念相似性,在图像聚类上,子图图像的误差更正能够被用来衡量两个图形的相似性。
将数据对象分到不同的类中是一个很重要的步骤,数据基于不同的方法被分到不同的类中,划分方法和层次方法是聚类分析的两个主要方法,划分方法一般从初始划分和最优化一个聚类标准开始。
CrispClustering,它的每一个数据都属于单独的类;
FuzzyClustering,它的每个数据可能在任何一个类中,CrispClustering和FuzzyClusterin是划分方法的两个主要技术,划分方法聚类是基于某个标准产生一个嵌套的划分系列,它可以度量不同类之间的相似性或一个类的可分离性用来合并和分裂类,其他的聚类方法还包括基于密度的聚类,基于模型的聚类,基于网格的聚类。
评估聚类结果的质量是另一个重要的阶段,聚类是一个无管理的程序,也没有客观的标准来评价聚类结果,它是通过一个类有效索引来评价,一般来说,几何性质,包括类间的分离和类内部的耦合,一般都用来评价聚类结果的质量,类有效索引在决定类的数目时经常扮演了一个重要角色,类有效索引的最佳值被期望从真实的类数目中获取,一个通常的决定类数目的方法是选择一个特定的类有效索引的最佳值,这个索引能否真实的得出类的数目是判断该索引是否有效的标准,很多已经存在的标准对于相互分离的类数据集合都能得出很好的结果,但是对于复杂的数据集,却通常行不通,例如,对于交叠类的集合。

二、如何利用R软件进行聚类分析
运用聚类分析法主要做好分析表达数据: 1、通过一系列的检测将待测的一组基因的变异标准化,然后成对比较线性协方差。
2、通过把用最紧密关联的谱来放基因进行样本聚类,例如用简单的层级聚类(hierarchical clustering)方法。
这种聚类亦可扩展到每个实验样本,利用一组基因总的线性相关进行聚类。
3、多维等级分析(multidimensional scaling analysis,MDS)是一种在二维Euclidean “距离”中显示实验样本相关的大约程度。
4、K-means方法聚类,通过重复再分配类成员来使“类”内分散度最小化的方法。
聚类分析法是理想的多变量统计技术,主要有分层聚类法和迭代聚类法。
聚类通过把目标数据放入少数相对同源的组或“类”(cluster)里。
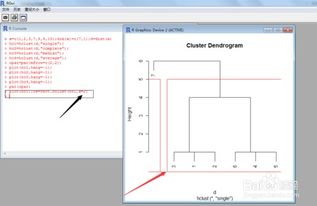
三、如何利用R软件进行聚类分析
1. 数据预处理,2. 为衡量数据点间的相似度定义一个距离函数,3. 聚类或分组,4. 评估输出。
数据预处理包括选择数量,类型和特征的标度,它依靠特征选择和特征抽取,特征选择选择重要的特征,特征抽取把输入的特征转化为一个新的显著特征,它们经常被用来获取一个合适的特征集来为避免“维数灾”进行聚类,数据预处理还包括将孤立点移出数据,孤立点是不依附于一般数据行为或模型的数据,因此孤立点经常会导致有偏差的聚类结果,因此为了得到正确的聚类,我们必须将它们剔除。
既然相类似性是定义一个类的基础,那么不同数据之间在同一个特征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特征标度的多样性,距离度量必须谨慎,它经常依赖于应用,例如,通常通过定义在特征空间的距离度量来评估不同对象的相异性,很多距离度都应用在一些不同的领域,一个简单的距离度量,如Euclidean距离,经常被用作反映不同数据间的相异性,一些有关相似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概念相似性,在图像聚类上,子图图像的误差更正能够被用来衡量两个图形的相似性。
将数据对象分到不同的类中是一个很重要的步骤,数据基于不同的方法被分到不同的类中,划分方法和层次方法是聚类分析的两个主要方法,划分方法一般从初始划分和最优化一个聚类标准开始。
Crisp Clustering,它的每一个数据都属于单独的类;
Fuzzy Clustering,它的每个数据可能在任何一个类中,Crisp Clustering和Fuzzy Clusterin是划分方法的两个主要技术,划分方法聚类是基于某个标准产生一个嵌套的划分系列,它可以度量不同类之间的相似性或一个类的可分离性用来合并和分裂类,其他的聚类方法还包括基于密度的聚类,基于模型的聚类,基于网格的聚类。
评估聚类结果的质量是另一个重要的阶段,聚类是一个无管理的程序,也没有客观的标准来评价聚类结果,它是通过一个类有效索引来评价,一般来说,几何性质,包括类间的分离和类内部的耦合,一般都用来评价聚类结果的质量,类有效索引在决定类的数目时经常扮演了一个重要角色,类有效索引的最佳值被期望从真实的类数目中获取,一个通常的决定类数目的方法是选择一个特定的类有效索引的最佳值,这个索引能否真实的得出类的数目是判断该索引是否有效的标准,很多已经存在的标准对于相互分离的类数据集合都能得出很好的结果,但是对于复杂的数据集,却通常行不通,例如,对于交叠类的集合。

四、如何用spss做k均值聚类分析
建议你直接去借本SPSS的书看,里卖弄有很多操作步骤和实例。
很快就可以学会的! 另外提醒你一点,在SPSS里面用聚类分析在里面的选项要选R型聚类。
否则的话结果是完全错的!当然你也可以先从把之前的矩阵进行转置,然后用K均值聚类。
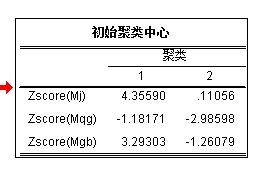
五、怎样对变量进行聚类?
你在这说的对变量聚类应该是属性聚类吧。
六、股票投资风险分析内容有哪些,如何掌握
股票投资风险分析,是个大问题,答案不一,因为每个人的分析习惯不一样,所以很难得到所谓的绝对正确的理论,我到【道富投资】上找到了比较符合的资料,如下: 一、股票投资风险概述 股票投资风险的基本原则风险控制的目标,其中包括确定风险控制的具体对象(基本因素风险、行业风险、企业风险、市场风险等)和风险控制的程度这两层涵义。
投资者应该如何确定自己的目标,取决于自己的主观投资动机,也决定于股票的客观属性。
在对风险控制的目标作出选择了之后,接下来要做的就是确定风险控制的原则。
根据投资者们多年积累的经验,控制风险可以遵循四大原则,即回避风险、减少风险、留置风险和共担(分散)风险。
二、股票投资风险基本原则 1.回避风险原则 所谓回避风险,即是指事先预测风险发生的可能性,分析和判断风险产生的条件和因素,在经济活动中设法避开它或改变行为的方向。
在股票投资中的具体做法是:放弃对风险性较大的股票的投资,转而投资其他金融资产或不动产,或改变直接参与股票投资的做法,求助于共同基金,间接进入市场等等。
相对来说,回避风险原则是一种比较消极和保守的控制风险的原则。
2.减少风险原则 所谓减少风险原则,是指人们在从事经济活动的过程中,不因风险的存在而放弃既定的目标,而是采取各种措施和手段设法降低风险发生的概率,减轻可能承受的经济损失。
在股票投资过程中,投资者在已经了解到投资于股票有风险的前提下,一方面,不放弃股票投资动机;
另一方面,运用各种技术手段,努力抑制风险发生的可能性,削弱风险带来的消极影响,从而获得较丰厚的风险投资收益。
对于大多数投资者来说,这是一种进取性的、积极的风险控制原则。
3.留置风险原则 所谓留置风险原则,这是指在风险已经发生或已经知道风险无法避免和转移的情况下,正视现实,从长远利益和总体利益出发,将风险承受下来,并设法把风险损失减少到最低程度。
在股票投资中,投资者在自己力所能及的范围内,确定承受风险的度,在股价下跌,自己已经亏损的情况下,果断"割肉斩仓"、"停损",自我调整。
4.共担风险原则 所谓共担风险原则,在股票投资中,投资者借助于各种形式的投资群体合伙参与股票投资,以共同分担投资风险。
这是一种比较保守的风险控制原则。
它使投资者承受风险的压力减弱了,但获得高收益的机会也少了,遵循这种原则的投资者一般只能得到平均收益。
希望能帮助到你!

七、如何用excel对数据进行聚类分析?
用excel对数据进行聚类分析的方法如下:1. 因为数据量纲不同将影响聚类分析的结果,所以在分析之前要对数据进行无量纲化处理,无量纲化处理的方法有很多种,我们可以根据自己的实际需要进行选择。
本经验示例较为简单,只需要对有序尺度数据进行无量纲化。
对于有序尺度,可以采用数值编码的方式将其转换为间距型。
如:优、良、中、及格、不及格2. 首选将外语的数据类型改成数值型,然后将各个数据属性值改为“5”,“5”,“4”,“4”,“4”,“2”分别对应之前的优,优,良、良、良和及格。
3. 指标类型中有“极大型”、“极小型”、“居中型”和“区间型”指标,所以在聚类之前必须对指标的类型进行一致化处理。
本例一致化处理见附图。
4. 选择“分析”--》“分类”--》“系统聚类”进入系统聚类设置选项卡。
5. 进入选项卡,将标准化后的数据作为变量。
然后可以在当中选择聚类的各种方式方法及要生成的图标,这里我们勾选上树状图后其他默认。
点击确定即可看到spss自动处理输出的结果。
6. 根据spss输出的结果进行分析。

八、如何用爬虫抓取股市数据并生成分析报表
推荐个很好用的软件,我也是一直在用的,就是前嗅的ForeSpider软件,我是一直用过很多的采集软件,最后选择的前嗅的软件,ForeSpider这款软件是可视化的操作。
简单配置几步就可以采集。
如果网站比较复杂,这个软件自带爬虫脚本语言,通过写几行脚本,就可以采集所有的公开数据。
软件还自带免费的数据库,数据采集直接存入数据库,也可以导出成excel文件。
如果自己不想配置,前嗅可以配置采集模板,我的模板就是从前嗅购买的。
另外他们公司不光是软件好用,还有自己的数据分析系统,直接采集完数据后入库,ForeSpider内部集成了数据挖掘的功能,可以快速进行聚类分类、统计分析等,采集结果入库后就可以形成分析报表。
最主要的是他采集速度非常快,我之前用八爪鱼的软件,开服务器采,用了一个月采了100万条,后来我用ForeSpider。
笔记本采的,一天就好几百万条。
这些都是我一直用前嗅的经验心得,你不妨试试。
建议你可以下载一个免费版试一试,免费版不限制功能,没有到期时间。

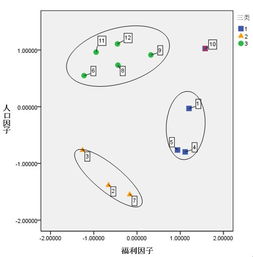
九、怎样用因子分析结果做聚类分析
按照因子得分做聚类分析
参考文档
声明:本文来自网络,不代表【股识吧】立场,转载请注明出处:https://www.gupiaozhishiba.com/article/33034242.html

